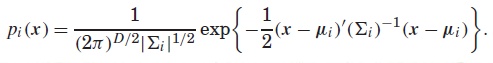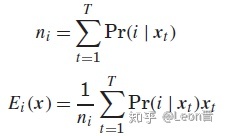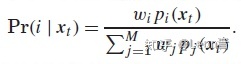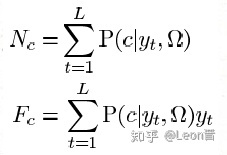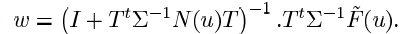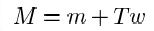2�������ʼ��UBMʱ��������M=2048����˹����components���ͻ���2048������˹������ÿ�� i ������i=1,2,...,M������һ��Ȩ�ء�һ����ֵʸ����һ��Э������� = {ci����i����i}�����Ц�i�͡�i�ֱ���ʸ�������
������ѧ������D=39ά����UBM�ĵ� i ����˹�����ľ�ֵʸ����������Dά��
����Ѿ�ֵʸ����Э����Խ���չ�������Ǧ�i = {��i1����i2��...����iD}����i = diag{��^(2)i1����^(2)i2��...����^(2)iD}������ֵ��һ��D x 1άʸ����������D x Dά�Խǣ�ȫ��������
4�����ݳ��ͳ���������ǻ��Ƚ�M����˹�����ľ�ֵʸ����ÿ��ʸ����Dά����������һ���γ�һ����˹��ֵ��ʸ������M x Dά������F(x)��F(x)��MDάʸ����ͬʱ�������ͳ��������N��N��MD x MDά�ԽǾ����Ժ��������Ϊ���Խ���Ԫ��ƴ�Ӷ��ɣ�Ȼ���ȳ�ʼ��T������һ��[MD, V]ά����VҪԶС��MD��V<<MD�����V���� i-vector ά�ȣ���ʽ���£�
���ţ��̶�T�����������Ȼ��MLE������������ w �����һ��ͳ�������ٰ��µ����һ��ͳ�����Ż�ȥ�����ʽ�ӣ���������w������ʹ���ලEM�㷨ȥ������������������5-6�Σ�������ΪT����������
��1��Speaker Verification Using Adapted Gaussian Mixture Models
��2��Front-End Factor Analysis for Speaker Verification ��3��SVM BASED SPEAKER VERIFICATION USING A GMM SUPERVECTOR KERNEL AND NAP VARIABILITY COMPENSATION