��ʵ�ϸ��¾Ϳ�������������ж�֪�������ݷ��� �����˺ö��ޡ�����ȻҲ������������Ķ�����������ԭ����ȫ��Ӣ�ģ�styleҲ�Ƚ����࣬���������ȽϷ��������ϵ����ڣ�������������ݵ�ת�������Ҽ�����һЩ�µ�˼����@���� ������������Ϊ��������ר���Ϸ�����ƪ֪�����ݷ��������£�����֪���dz��з����ļ�ֵ ��������һ��Course Project������������Ŀ�������������ᵽ�ģ����С��Ŀ��ʵԶԶû�ﵽ��������ij̶ȣ��ڵ�̫dz��ʵ�ʴ�����������Ҳ��С������ʵ�ǻ����������ȥ�ġ������κ����⾴��ָ��������֪����Ҫ�ڴ˻����ϼ�������ɶ��Ҳ������֪����֪���罻����������ϣ�������ͳ�� ֪���罻����������£�����ע���� 1.0 ��� ����Դ������2015��Social Computing �γ��в����һ��С����Ŀ����Ҫ����ΪPython����Ŀ��ԭʼ����ΪӢ��д�����������˴���ȡ֪������һֱ������������������� ���ڱ������Ҵ�����ȥ������ȡ�����ݿ�I/O�IJ��֣��ص��ڷ���һЩ��Ȥ�Ľ��ۡ������������в���֮��������ָ����
Ϊ��֤�ɶ��ԣ����Ľ���Ϊ������ƪ��һƪֻ�漰���ݽ��ܼ�������ͳ�Ʒ��� ����һƪ�������û���ע�����ע������еķ��� ��
��������С��Ŀ��ȫò����Ȥ��������Ҫ�Լ�fork�������棬��������Ŀ��Github������ �����ݵ�ѹ������������������ ��ʹ����ע����ԴΪ����ҳ�棩��(����ʱ�侫�����ޣ���Ҫ����ԶԶ���Ѿ����˵Ķ࣬������Ҳ�ܲ��������⣬�����ͯЬ����Ȥ��һ�������~)
1.1 ���� ���Դ��²�ģʽ������
��˵����������ȡ����Ҫ˵���������ʹ�õ����ݵ�����ɶ�����ǵü���һ�µġ�2015��10�£�����ʹ�������˵�֪���˺� ��Ϊ���ӣ��Ȼ���������ҹ�ע���û������ݣ��ٻ������Щ�û�����ע���û������ݣ������������ӵĻ�һ����3��Ĺ�ȱ��� ��ע����ʵ������ݿ����Ǵ�������bias�ģ��Ͼ�seed��һ�����ƣ����ƹ�ע������...����ô�о�����һ������������û����ݰ������û��Ļش������û���õ���ͬ������л�����û���ע���˺�ע�û����ˣ��û��ش���������Լ�ÿ������Ļ����ǩ������������ݵļ�Ҫͳ����Ϣ��
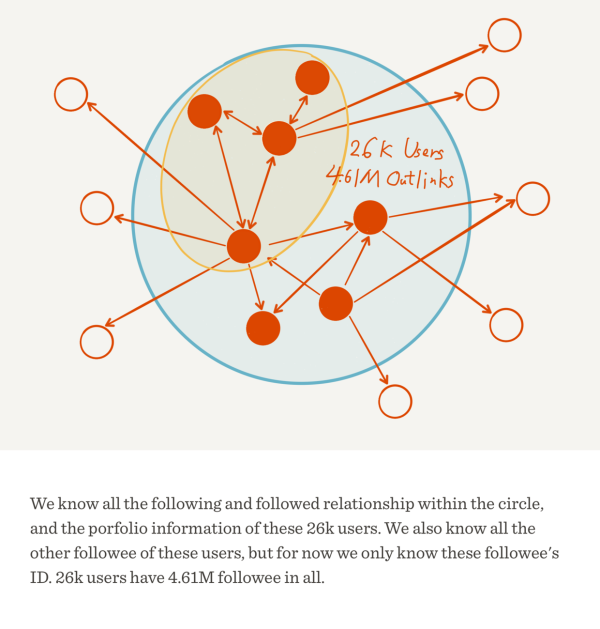
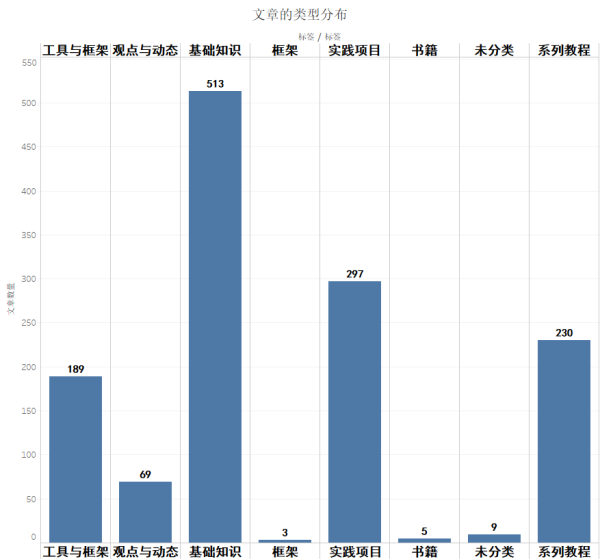
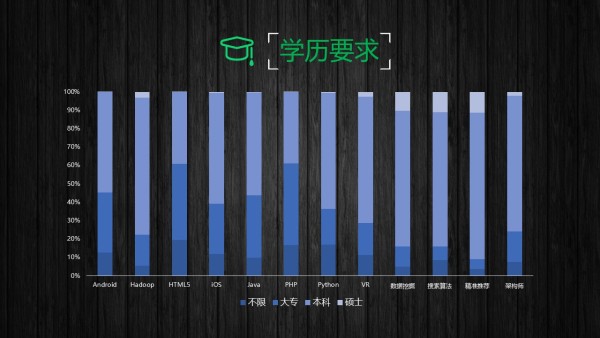
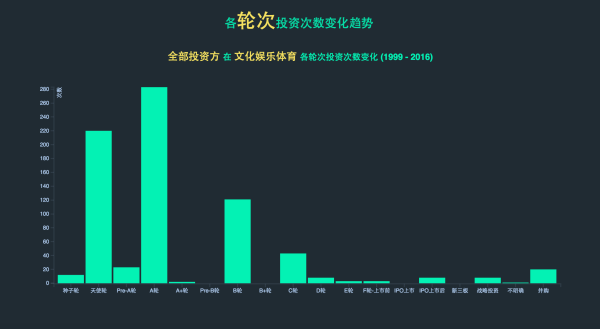
���ݿ��ļ�: 688 MB��SQLite�� ���ݰ�����2.6�����û�, 461������ע����, 72������� ������һ������ȫò��ͼʾ��
���潫���ؽ������������ķ�����
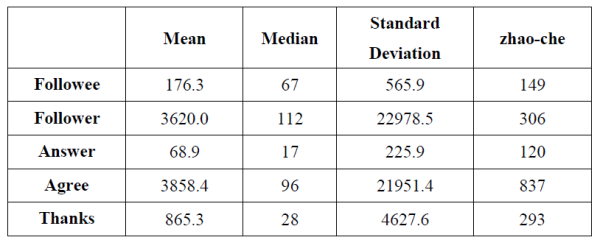
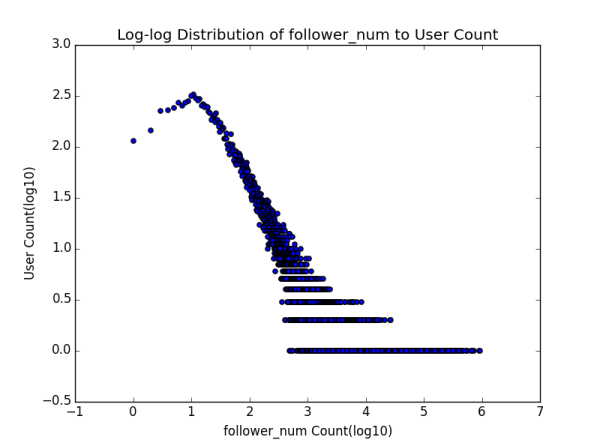
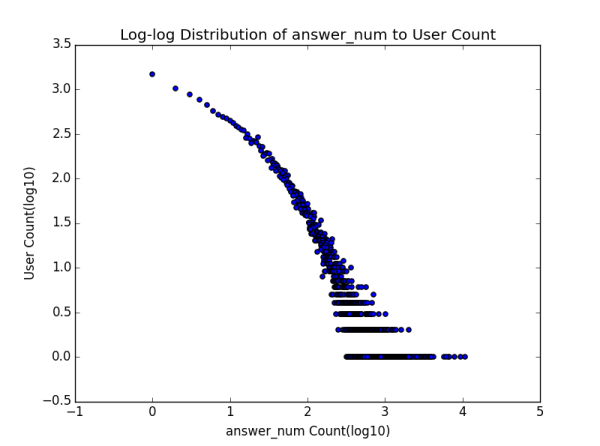
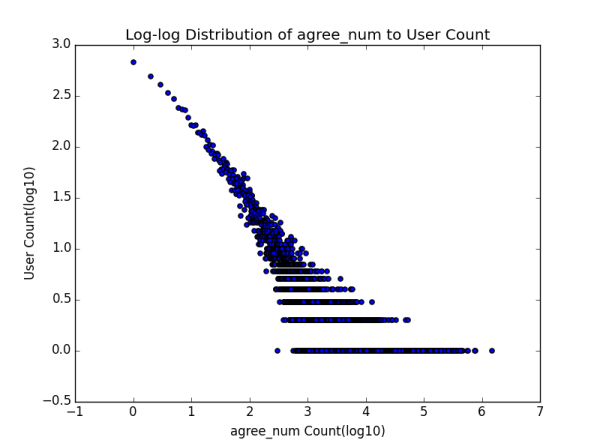
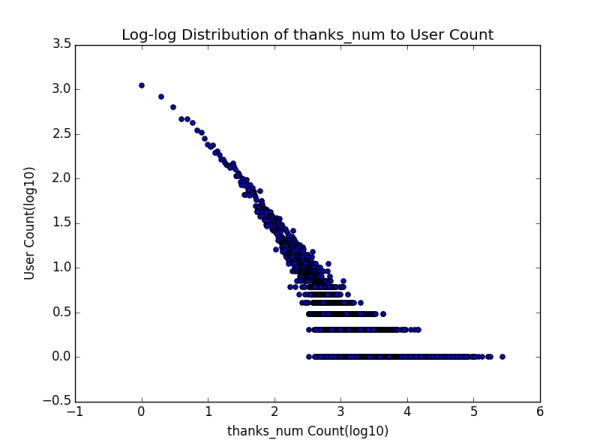
1.2 ��IJ���ͬһ��֪������ֵ����λ������� Ҫ���߱���������֪���ϻ��������������ļ���ָ����ʲô�أ�һ���ǹ�ע���ش���ͬ����л�������������ȶ��û�����ע����followee�� ����ע������follower����˿���� ���ش�����answer�� ���յ���ͬ����agree�� ���յ���л����thanks�� ��ƽ��������λ���Լ���������˼��㣬������±���
������ʵ����������Ȥ�Ľ����ˡ�
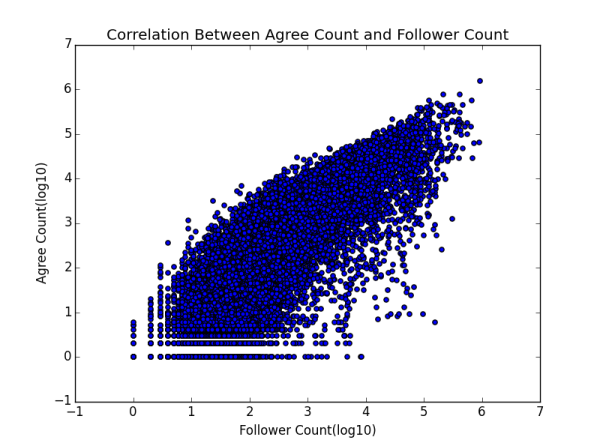
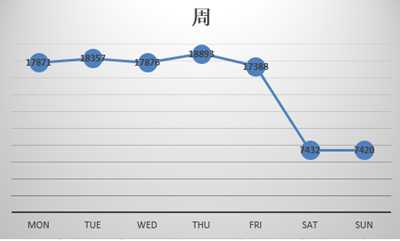
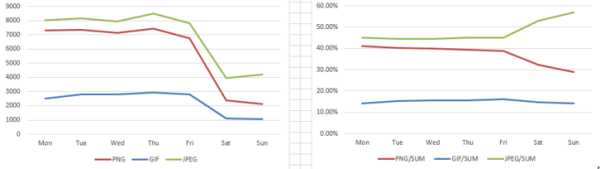
�������ǿ�ƽ��ֵ���ۣ�ƽ��ÿ��������ǧ���˿����ǧ����ͬ���ٿ����������ң�306���ۺ�837���ޣ��������ǻش������Ҳ�����డ��ȴ����ô���ͷ�˿�����ò�������֪���ˣ��ٿ�����λ������ʱ�������һЩ�ˣ�ԭ���һ��ͦ��������ָ�궼���ұȽϴ��濪�ģ����Dz���ɵ����
������ʲôԭ�����ƽ��ֵ����λ��������ô���أ�Ҳ�������ܴӱ������һЩ���ߡ���̫���ˣ���˿������ͬ���ı�����������������
����ζ��ʲô�أ�����֪����������ʵ���������ݸ���֮�����ɢ�̶ȣ�Ҳ���Խ���Ϊ�ֵ���ֵ����ƽ��ֵ֮��IJ��� �������ô��ı������˵��֪���û�֮��IJ������Դ�����������ϵ��������ͬʱҲ˵�������û�����ֵ��ƽ��ֵ�кܴ�IJ�࣬Ҫô������ף����磩��ҪôС�ÿ����������ң���
���˿��ܻ������˵�����������������ݱ�����scale�����ܳ��˵�����⡣��ô����ʹ�ñ�����ʣ��������ƽ��ֵ����������ͬ����21951.4/3858.4 = 568.9%����~��~��~��~��~��~��~
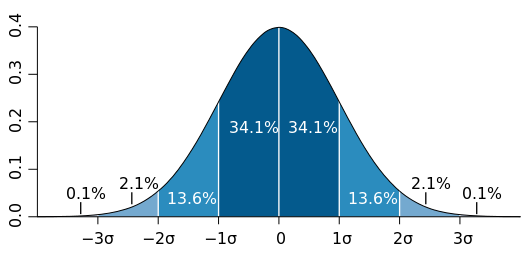
���������Ե���һ���²⣬�Ǿ���֪���û��������ָ���ֵ�ֲ����������������̬�ֲ�������� �������ǻ�����̬�ֲ������ӣ�
https:// zh.wikipedia.org/zh-cn/ %E6%AD%A3%E6%80%81%E5%88%86%E5%B8%83 �������̬�ֲ�����λ�������м��ֵ��������������ֵ���Լ�ƽ��ֵ��������Ӧ���Ƿdz��ӽ��ģ�Ȼ����������ȴ�ǵ��¾��루��ôһ����ˮ��ô�ࣩ��
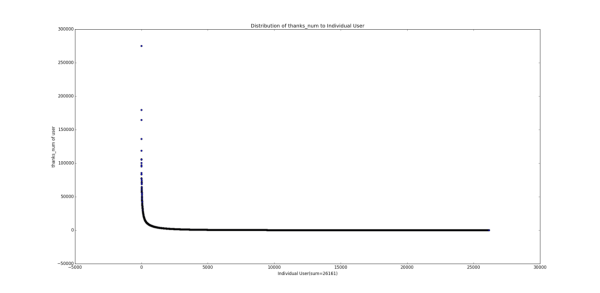
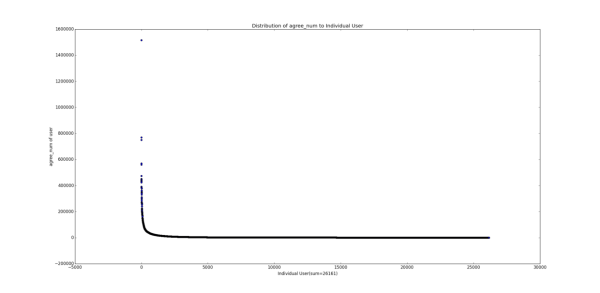
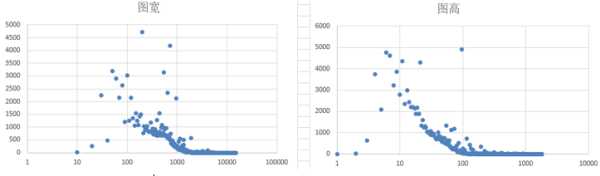
1.3 ��ѩ��������β�����ɷֲ� Ϊ�˽�һ����֤1.2�IJ²⣬���ǻ��������ָ��ķֲ�ͼ��Distribution Graph����
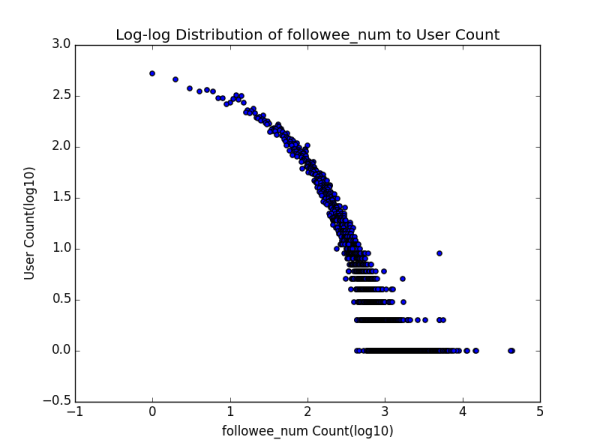
����˵��һ�������ŷֲ�ͼ�ĺ��壬�����ʾָ��ľ�����ֵ�������ʾ�ж����û����и�ָ��ֵ����Ҫע����Ǻ���ֵ������ֵ��ȡ����10Ϊ��log�������о���һ�ֳ����Ĵ����취���ܹ�ʹͼ���������Ϣ���������Ը�л���ֲ�ͼΪ�����Ǹ������Ϸ��ĵ��ʾ���������֪���û����棬�д���10�����η�Ҳ����1000����û�л��һ����л������������������һ�ŵ�����˵����л����x1��x2��...�� xn (��������С)���û�����ֻ��һ���ˡ���ע�����һ�ŵ㲢�����γ�ʲô��Ч�Ľ��ۣ���Ϊ���ܸ�л��100��ֻ��һ���ˣ�101�ľ��кö����ˣ���һ���̶��ϴ������Ϊ������С���������� ��������������漸�ŵ�ŵ�һ���ǣ�Ҳ�����������һЩ��
˳����һ�䣬��ʵ��ע���ͷ�˿���ķֲ�ͼ�ֱ�������һ�����֣�������ʵ��֪���û���ע����ij��ȣ�out-degree���ֲ�ͼ����ȣ�in-degree���ֲ�ͼ ���������ƪ�л��������ᵽ��
����Ƕ����ֲַ�ͼ�Ƚ���Ϥ��ͯЬ��Ӧ��һ�۾��ܿ���������ڲ�����̬�ֲ��������п��������ɣ�power law���ֲ� ��������Ϊ�����Dz�û�������ȥ��֤�������ֲַ����������˲������е������ж�����֡����⣬��ϸ�Ƚ����������ߵ�������״ ����û�о����������������������в�ͬ��һ���ǹ�ע����һ���Ǵ�������������������������̶��ƺ������ԣ�Ҳ����˵���ź���ֵ����������ֵ��С��������Խ�������ǡ�����ָ����ֻ����������ij���û��Լ����Կ��Ƶģ�����������ָ�������������û��γɵ�Ⱥ�������ƣ����Ǻ������һ�㣬�Ҿ�����ʵ�������ڵĿ����ԡ�
�����������Ը�л��Ϊ�����ٻ�����һ�ֲַ�ͼ�������ʾÿ���û���indexҲ����0��1�� 2�� 3...��˳���ɸ�л����С�������������Ǹ��û��յ���л���ľ�����ֵ��
�����Ǹ�ͻ����ʵĵ����𣬶�ʮ�߰���ĸ�л����ʵ�������ǰ�����Ÿ�л���ֲ�ͼ��Ҳ�����ˣ��㻹�ϵý��ڼ�����Ȼ����������𣩣��ٿ�����������������β�ͣ��˼�Ī��������һ�������ŵģ���ͬ����
��������ָ���ͼ����״Ҳ������ˡ�
������ʹ��Զ�������ǵ��������������Ƶķ��� ��������һ�µġ��ܽ�һ�¾��ǣ��������С�ÿ�����ȴ�м������˴�ÿ��£�һ��Ҳ�������ɣ�̬��������ǰ���겻���б���ܻ��𣬽�������β���ۡ�����ν��β ��ָ�ľ�������һ���������ҶԸ������һЩ���ͣ�ʲô�ǡ���βЧӦ�� �� - �Գ��Ļش� ��
�����ﲻ�ɵ������ᵽ����һ����������̫ЧӦ ����ν�����Խ��Խ�������Խ��Խ�����о�����ʵ���dz�βЧӦ�Ķ�̬���ͣ�������㿴����û����ص����ף������������մ�����Դ����˸����ܾ�ȡ������Դ������������෴����V��Ϊ�������õ������ע��ͬʱ��˱�ø�������������Ϸcarry�Ӷ��õ�����Ǯ������Ǯ��װ���ָ�����carry�����ǵ��͵�������������ѩ�������������ɵĽ�������dz�β����
1.4 ����ι�������Ӯ�ң���ͬ���ע ��һ�ڿ������Ƕ���һ�ڽ��۵�һ��֧�š���������ͼͬʱ�������û�����ͬ���ͷ�˿������ָ�꣺
��!�ܼ��־�֢����Ԥ��! ��
���벻��Ҫ�����������ع�ʲô���ˣ�һ�����dz����������ذ�����ҲΪ�ҵ������������Ϯ��Ϊ֪����V�ṩ������֧�֡���Ҫô����б��»ش����������ͻ����ʵĴ𰸣�Ҫô��һ��ʼ�ͺ�������ûдɶ��Ҳ������...��˵�Ķ���ƨ��...��
2.0 �罻������ʲô�� ����ƪ�����Ļ�����ͳ�Ʒ���֮�������Ѿ���֪���û�����л���ĸ�����������������һЩ�˽⡣���ڣ�������������������һ�����⣺����ƽ����˵���罻�������˵������磬������ʲô��˼��Ҳ����ὲ�������ֻҪһ�������ж��˲��룬��Ȼ�ͻ�����罻�����ʣ��Ӷ������罻���硣��ô������˼��˼����ά���ٿ��㲻������罻���ʣ�
ά���ٿ�ȷʵ�кܶ��˲���༭��������������Щ��֮����û�и�ֱ�ӵĻ����أ�����༭����ͨ��QQ����֮����л������Dz��������罻�����㲻����ά���ٿƱ��������е��罻�����أ���ʹά���ٿ��ṩ������֮��Ĺ��ܣ�����ʹ�༭��֮��ֱ�ӻ�������Щ������Ȼ�ǻ���ij�������ģ�ֻҪ�������ûʲô�������ˣ�����������Ҳ�����ű༭��ֹͣ��ֹͣ�ˡ�����Ϊ������ʱ���������Ĺ�ϵ�������õ�һ����Ϊ�ȶ����罻���硣
����������˼��һ�����ӡ�����֪����һ�ſ�ѧԴ�Կ�Խʱ���������˵Ĺ�ͬ���ף���ô�������ˣ��ܹ������罻�����𣿵�Ȼ���ܡ���νţ�ٺͰ���˹̹�ĶԻ�ֻ��һ���ǣ�һƪ�Ѿ����������ģ����������һƪδ�������ģ����ǵ����ǿ��ǵ�ͬһʱ����ͬһѧ�ƣ������������ͬ��ѧ��֮��ȷʵ�����Ÿ��ֽ��������Ŀ��ܣ�������ǿ�����Ϊѧ������Ĺ�ͬ���߹�ϵ��Co-authorship���γɵ�������ʵ�Ǵ����罻���ʵġ�
�����ϴ��Ե�˼�������ǻ��������ܽ��γ��罻����ļ����������������ֱ�ӻ����������ij����ԡ������Ľ�ͬʱ�� ��
�������������»ص�֪������������ͬ����л���ش𡢹�ע����һ���û���Ϊ���������������������ش��ǻ�������ģ�֪���IJ�Ʒ��Ʋ���ͻ����˭�����ij�����⣬����һ��������Ա���ͬ���˽��б༭������ά���ٿƵ�Ȩ����ƣ���Ҳ����˵�ش���һ�㲻��������˭��������⣬���Իش����������Ʋ��ϣ���ͬ����л�Լ�����֮ǰû���ᵽ�����ۣ������˵��������ֱ��һ�㣬�������һ�����£������г����ԣ�ֻ�й�ע��ϵ��ͬʱ����������������������ܻ���һ�����ʣ���עҲֻ�������ôһ�㣬�����㳤�ڵ��𣿲�Ҫ����֪����ʱ���ߣ�Timeline�����ƣ���ʹ�ù�ע���и���ĸ��ʿ�������ע�ߵĻ����֮���л���������ֻҪ��ע��ȡ�������ֶ�ʱ���ߵ�Ӱ����dz��ڵġ�
���ˣ����ǿ�����Ϊ�������Ҫ��֪�����罻����ĽǶ��Ͻ��з��������ȾͿ��Կ���֪���û�֮��Ĺ�ע��ϵ����������ʼ�������ǶԴ˽��еľ��������
2.1 ��������ͷ������� �������˽�һЩ����Ļ���֪ʶ��
һ��������Ա���ʾΪһ��ͼ��graph�������а����㣨vertex / node����ߣ�edge / link�����ֻ���Ҫ�ء� �߿��Ծ��з����ԣ�Ҳ����˵����һ������˵�������������ߣ�out-link���������ߣ�in-link�����ֱߡ�������Ǿ��з����Եģ���ô����ͼ��Ϊ����ͼ��directed graph������֮��Ϊ����ͼ��undirected graph����ͼ��ӳ�˵����֮���ij����ع�ϵ�����ֹ�ϵ�ɱ߱��֡�
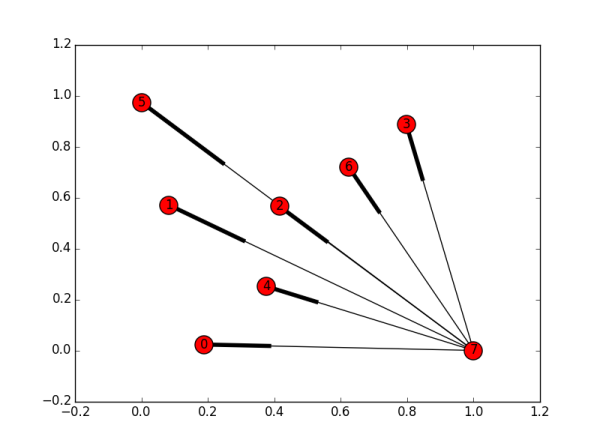
�ص�֪���ϣ�����֪����ע�ͱ���עʵ������һ������������Ƕȡ�A��ע��B���ȼ���B��A��ע������������ȡ�������У���1.1�е�����ȫòͼ��������֪����2.6���û��е�ÿ���˶���ע����Щ�ˡ�Ҳ����˵������֪����2.6���û�������������ߡ�����һ���Ƕ��룬������ʵҲ֪������2.6���û�֮��˭��ע��˭����Ȧ���ڵIJ��֣������� ���ǹ�ע������ʲô�ˣ���Ȧ����IJ��֣����������ֻ�ܷ�����2.6���û�����ɫʵ��Բ������Ϊ���Dz���֪���������ˣ���ɫ����Բ�����������ӣ����������ǵĹ��������ȡ���������µģ�������֪����վ���������������������ݣ���Щû�˹�ע���˺�Ӧ�ÿ��Ժ��ԣ���
���⣬��ʹ������Ȧ����IJ��֣��漰����������Ȼ���кܴ������������������һ�����⣬�����������Ŀ�У����ǽ���ѡȡ����2.6���û���������Ȥ���Ӽ����з����������ͬ������1����û�����1895�ˣ��������ͬ������5����û�����375�ˣ���������������ǽ����Ƿֱ�����ΪNet10k ��Net50k ����ʵ����˵����������ͬ�����֪����VȺ�� �ˡ�
��������������������һ������ͼ��������ֻ�е�ͱ����ֶ�������ʵ���������ӵ�����ĸ������������ʡ�������������߽�һ��˵������������֮�У����ڴ�������Ϊ��������������������ĸ���Լ�Ϊ�������������������Ƶ�ָ�ꡣ���Ľ�Ҫ�漰�ķ��������������������һЩ�����ָ���ϣ���������������ϸ���ܣ���ô����ƪ������ӳ������һ���������ѧ��ʽ���ⲻ�����ҶԱ��ĵ�д��Ԥ�ڡ�����Ҵ��㾡����ֱ����intuition�������������Ƿֱ������ʲô�ĺ��壬��ʹ��������Ҳ�����ϸ���ѧ��ʽ�ſɴ����������ϸ�Ķ��壩���ص����ڶԷ�����˼�������⣬�������������۵�֪����ע����������ͼ���������е�ָ����㷨��ֻ��������ͼ�� ����Ȼ�������������һ���Ļ���������ֱ��������صĶ��䡣
2.2 ���ŵĴ�V�ǣ������������� һֱ����֪������һ��ӡ���Ǿ��Ǵ�V��ϲ�����š����ע�ҡ��ҹ�ע�������ֹ�ע�㣬�γ��˽��ܵ�Ȧ�ӡ���ô������������������������
������A��B��C�����û���ɵĹ�ע���磬����Ψһ�ı���A->B����ô�������������Ƿ���ܣ����ǿ��������룬������֮����������6���ߣ���ô���ǿ�����1����6����ʾ�������Ľ��̶ܳȡ����6���߶����ڣ���ô���̶ܳ���1������������Ϊ0���������νͼ���ܶȣ�density�� ��Net10k��Net50k���ܶȷֱ���0.064��0.195���������ǿ��Բ²⣬�����ͬ����Ĵ�V֮�䣬��ע��ϵҲ��Ϊ���ܡ�
���������Ǵ���һ���Ƕȿ�������²⣬�Ȳ��伸�����壺
����ȣ�degree�� ����һ����ͨ����������������������ͣ�����Ϊ�����Ķȡ�����ͼ��һ������ڳ��Ⱥ���������ȣ�һ��ֻ�����ܵ����ĸ��㣬һ��ֻ����Щ���ܵ�����������֪���Ĺ�ע��ϵ���ԣ����Ǻ������ܿ������Ⱦ������ע����������Ⱦ��ǹ�ע���������
�����֮���·����path�� ������ӵ�A����������һ����������ߣ������˵�B����ô���dz���Щ�߰�˳�������γ���һ��A��B֮���·����������·������һ���Ǵ��ڵ���0�ġ�����ÿ���ߵij�����ȣ���ô�����������ٵ�·����������ν���·����shortest path�������·���ij���һ�㱻��Ϊ������֮��ľ��루distance����
ͼ��ƽ�����·�����ȣ�average shortest path length�� ������һ��������ԣ������е�����֮������·�����Ƚ�������ƽ�����õ��ľ�����νƽ�����·���������������������е�֮���ƽ�����롣��˵�е����ȷָ���Six Degree Seperation������ʵָ�ľ���һ�������ƽ�����·������Ϊ6�������ҿ�������ߡ��Ⱥ�·���������ϵ����
���ƫ���ʣ�eccentricity�� ������ͼ�е�����һ��P�����������������������·�����ȣ����룩���������ľ��������P��ƫ���ʡ�
ͼ���뾶��radius�� ��ֱ����diameter�� ��ͼ�İ뾶��ֱ���ֱ���ͼ����С�ġ����ĵ�ƫ���ʡ�ע��ͼ��ֱ������Ȼ�ǰ뾶��������
ͼ��ǿ��ͨ��ͼ ��strongly connected subgraph�� ������һ������ͼG��һ����ͼG'����ζ��G'�еĵ�ͱ߶�ֻ�ܴ�G������������ÿһ���㶼��ͨ��ij��·��������һ���㣬������˵G'�߱�ǿ��ͨ�ԣ�������G��һ��ǿ��ͨ��ͼ������ע�⣬����һ��������Ҳ��Ϊ��ǿ��ͨ��ͼ����Ȼ�����㲢û��ֵ���о��ģ�
ͼ��ǿ��ͨ���� ��strongly connected component�� ��G��һ�������ǿ��ͨ��ͼG''����ζ������G''���κ�G��ʣ�µĵ㣬�����ƻ���ǿ��ͨ�ԣ�����ΪG��һ��ǿ��ͨ������������Ҫע�⣬���������ܴ�
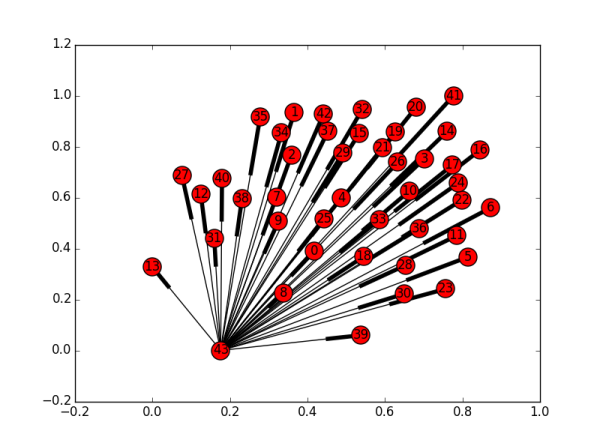
�ֺö���˰ɣ����ڿ�����ͼ��������ֱ���Net10k��Net50k��ǿ��ͨ����ʾ��ͼ��
�ܽ�һ������֪����ʲô��
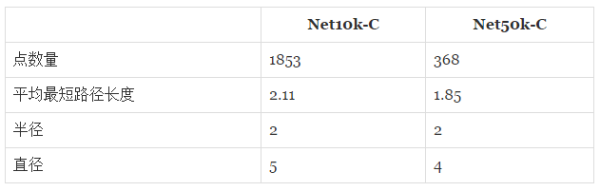
������Net10k��Net50k������ͼ����ǿ��ͨ�ģ���˵�����ˣ����Ѿ�������������һ�� ���ðɣ�һ��Ȧ�ӣ��� ����һ�����Ȧ�ӣ�Ⱥ�����ʣ�����������еĸ����V������ֻ����һ�����ǿ��ͨ�������������ܵ���������V�Ĺ�ע����ȴû���κλطۡ��������У����ֵ�Ҳ����Ϊ���ҵ㣨dangling nodes�� �� ���������ص������������ǿ��ͨ��������ͨ������ͨ���������AҪ����100���˲��ܵ�B���ǹ��ƹ�ƾ��ע��ϵ��������û��Ե���ˡ���Net10k��Net50k�����ǿ��ͨ�����ֱ�����ΪNet10k-C ��Net50k-C �����������߶�Ӧ��ָ�����ݣ�
��������Net50k-C�е�һ����V��������ʶ���е���һ����V��û��ϵ�����ע�Ĺ�ע�Ĺ�ע...�ܻ������������������л��ῴ���˴ˡ�ǿ��ͨ��֤���ܻ���һ��·����ƽ�����·�����㱣֤ƽ����������·���̣ܶ�ֻ��2���ҡ�ֱ���Ͱ뾶��������������� ����������������Ȧ���������Զ����λ�������������·�ij�����2��5��4��֮�䡣What a small world��ϲȵ�ǣ���������˵��
2.3 ����V�Ÿ�λ���������ӷ��� �Ͻڲ����ڶ�֪����V��ע�����������з��������Ȼ����Ȥ������������Ȥ�����������֮�е�ÿ�����壬ͬ������ͬ���ܸߵĴ�V�����DZ˴�֮���Ƿ���һ�ϸ����أ������ڹ�ע�����罻��Ϊ���Ƿ���в��죬��κ������ֲ��죿���DZ����漰�����⡣
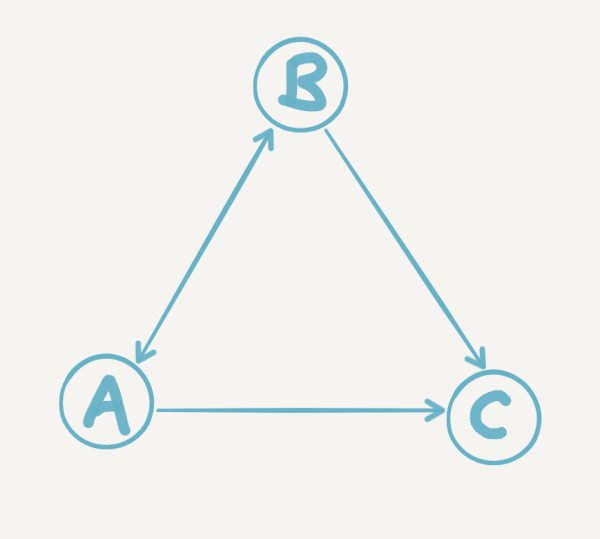
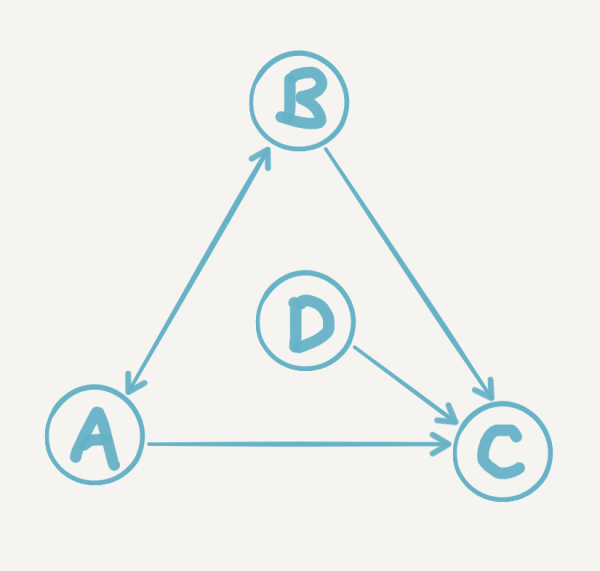
��������������һ���Ĺ�ע���磬����ֻ��A��B��C�����ˡ�A��ע��B��B��ע��A��A��Bͬʱ��ע��C����C˭Ҳ����ע������ͼ��ʾ��
��ô����ù�ƾ��ע��ϵ������A��B��C˭����ţ������ֱ������˵��Ȼ��C����ΪC������֮�еõ������Ĺ�ע�����Ƿ�ֻҪ��˿�������˵������ţ���أ������������������Ļ����ϣ������Ǽ��ֺ���Ȥ�������
����10���Լ���˿��Ϊ0���û���ͬʱ��עA ����10���û������DZ˴�ȫ�������ע������֮�ⶼû��������˿ ����10���Լ���˿��Ϊ1���û���ͬʱ��עA������ÿ���˻��ֱ��ע��10000�������û� ��������˵1���A������2���10���û���C��ţ��ǰ����������Բ��ϵ���������˵�ǽ�Ϊ���͵�������Ϊ������������������˿�������©����û�п��ǵ�ÿ����ע���ӵ��������� ���������������һ�����������������ã���Щ�û�һ����ֻ��1����˿����������0����һ�������ǹ�ע����ô���û�����ô���ǹ�עA��������ΪA����Ҫ��
��Ȼ������©������ô���粻������ͬ�����������أ������Ƿ��п���ͨ����ע���籾�������Խ���أ���ֱ������˵�����ǿ����뵽���ǣ��÷�˿�Լ��ķ�˿�����������������˿������������˿�ķ�˿����������Ҫ��˿�ķ�˿�ķ�˿������������...��ô��������Ǹ�ʲô��������������ǿ������ճ����Խṹ���ܳ��ص�˼ά���֮dz�� ����һ�������������Ӷȣ�������Ȼ�����������ò������и�����ѧ��
PageRank�㷨 ������Google�Ĺ�ϵ�ҾͲ����ˣ�����һ����ѧ�Ϸdz������Ĵ𰸣��������ǵ�ǰ���������������⣬�������������������������۹�ע������ʲô���ӵģ�����֤�ܵõ�һ��������û���Ҫ�̶�����
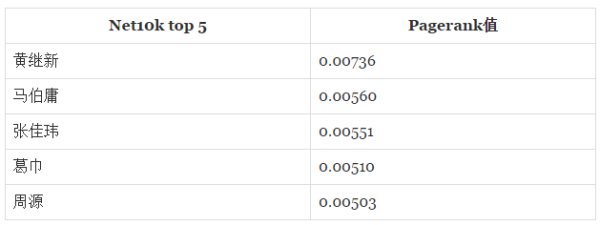
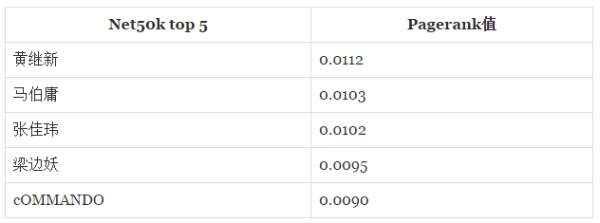
���������Ƕ�Net10k��Net50k�ֱ����PageRankֵ��ע������ֻ���Ǵ�V���ڲ������ӣ�����Ȧ�������д�V��PageRankֵ��ӵ���1�����õ�����ǰ���֪����V�û����£�
��Щ����վ��֪����V�۷�Ĵ�V���ˣ��Ƿ������һ�������أ�ע��Ƚ�Net10k��Net50kǰ���û���PageRankֵ��ǰ�߱Ⱥ���С������Ҫ����Ϊ�ܺ�Ϊ1��PageRank��Դ������Ĵ�V�Ƿֵ��ˡ�
�����������ٿ���һ�㣬��ν�ġ���Ҫ������ʵҪ�����ǵ�Ŀ����ʲô������������Ҫ������ĺô𰸻�����Ҫ���˳���Լ�壬��ôֱ���ҵ��ô𰸵Ĵ����ͺã�����Щ�����������������Ĺ�ע���������ǽ�����Ҫ֪��˭�ܵ��Ĺ�ע��ǿ��������ͼ�е�C����
���ǹ���ͨ����ע�����ǻ�©����Щ��ʱû�еõ�̫ǿ��ע���ô��� �������Ǹոռ���֪���Ĵ�VDZ���ɣ���Ȼ�������ֲ������Լ�ȥһ��һ���ھ���Щ�ô���������Ǻã������������ҵ���������ǣ���� ���û���������ͼ�е�D��������ֻҪ�����ǹ�ע���û��������������������ζ������ͼ��ˡ���ֻ��Ҫ��ʱ�������Ƕ���ע��˭�����ܷ��ָ�������硣����ʵҲ����һ���û��Ƽ�ϵͳ�Ŀ���˼·������Ͳ�չ���ˡ�
HITS�㷨 ��������ֻʹ�ù�ע���磬ͨ��Ȩ���ȣ�Authority�� ����Ŧ�ȣ�Hub�� Ϊ���Ƿֱ������õĴ������ͺõ�ǣ���ˡ�
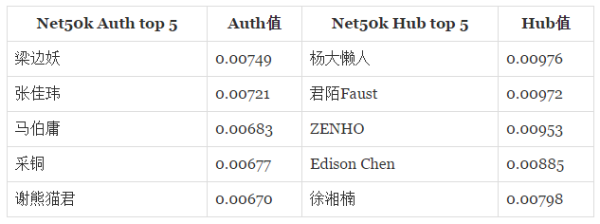
����Ļ���ֱ���ķ����Ƿ�˵��ͨ�أ������ǿ���Net10k��Net50k��Ȩ���Ⱥ���Ŧ��ǰ������
Auth���ô��������棬�����Ŵ��Ӧ������ͬ�����Ľ��������ֵ��һ�������������VȺ��֮�У�@�ż��� ��˳����һ�£��ż����Ź��Ӿ�����ƪ���Ǹ��ڸ��������и߸����ϵ��������㣩��@������ ������λ�ã�����Ȥ��������Net50k�У�@��ͭ ��ʦһԾ����ǰ�壬@����ӹ ���������������⣩����һ�����Ƽ�������˳�ȥ����Щ���������ӳ����ͬ��VȺ���һ��ϲ������IJ��� ��
Hub��ǣ���ˣ����棬˵ʵ���Ҹ���ֻ��ʶ@����� һ���ˣ����л���һλĿǰ�����˺�ͣ��״̬������㲻�����������ֻ��һ��Ƚ���Ȥ����Ϊ��V����˿���ܴ��������Ȼ����Щ�û���ע������Ҳ���Ǻܶ�ģ��ü��������ﵽ�˼�ǧ�����ɲ�ν֮����ij�ֽ��ʻ����ԡ�������һ�£�Net10k Hub�ĵ��������иɴ�����û������Ѿ���֪����˭�ˣ�ԭ�����û�ID��wang-wang-wang-08-18�����ڸĵ��ˣ��ܾ��ø�����骣�ID��miaomiaomiao��֮�������ij����ϵ...
�ۺ�������HITS��PageRank�в�����ͬ���û��������Ϊʲô�أ��Ҹ�һ��ֱ��������Ϊ�ԵĽ��ͣ���ʵPageRank��ֵ��Hubֵ��Authorityֵ��һ�ֵ��ӣ���ʵ�о������dz˵Ĺ�ϵ����Ľ��������Hub��Auth�е�һ�ֺ�ǿ����һ��Ҳ����ʱ��PageRank����Ӧ�Ƚϸߣ����������㷨�õ�������ͬ�Ľ����������ˡ�@�Ƽ��� ��һ�����͵����ӣ�����Authֵ��Hubֵ��Net10k��Net50k����Ȼ��������ߣ������ŵ�ǰ20����������PageRank���ǵ�һ���������ݣ����ܳ䵱������
2.4 �������еľ��⣺Closeness��Betweenness���Ķ� �������������ܽ�һ�£����Ҫ����һ���û��ڹ�ע�����еġ���Ҫ�̶ȡ������ǿ��������⼸��ָ�꣺
���û��ķ�˿��������ȣ�In-degree�� ���û���PageRankֵ ���û���HITSֵ ���������������Ҳ�ɱ���Ϊͬһ��ָ�꣺������Ķȣ�Centrality�� �������Ƿ��֣���ʵ����ָ��������ġ���Ҫ�����京���Dz���ȫһ���ģ�ͬһ�����磬ͬһ���ڵ㣬���ܲ�ͬ�����Ķ��������в�С�IJ�ࡣ�������������ҽ��ܱ���Ŀ���漰����������ֵ�����Ķȣ�
����������Ķȣ�Closeness Centrality�� ��һ����Ľ������ĶȽϸߣ�˵���õ㵽��������������ľ���������˵�Ͻ�����֮���Զ������һ�������ֿ�������Ҫѡij���ֿ���Ϊ������תվ ����Ҫ���������ֿ�ľ���������˵�������ôһ�ַ��������ҵ��������Ķ���ߵ��Ǹ��ֿ⡣
����������Ķȣ�Betweenness Centrality�� ��һ����Ľ������ĶȽϸߣ�˵��������֮������·���ܶ�����ȫ�������� ��������ת�������������ʧ�ˣ���ô������֮��Ľ����������ѣ��������ܶϿ�����Ϊԭ�������·���Ͽ��ˣ�����˼���Ҫhackһ������ �Ļ������ĸ���������㶮�ġ�����һ���Ƕ��룬��Щ���ֱ����������˿��֮·�ϱؾ��ؿڵ�ǿ�� ����������·Ǯ��������·���ߣ�����ͱ����ˡ�
���������Ķ���Ŀǰ��δ�ҵ��ܹ��ϵ����ķ��룬�����Լ������ˡ�����ͬPageRank��HITSһ��������ָ��ļ������Ը��ӣ�����Ͳ���ϸ�����ˡ��������Ƕ�ʹ�õ������������Networkx�е��㷨ʵ�֣�����ϸ�㷨����Ȥ�Ķ��߿����в������ĵ���
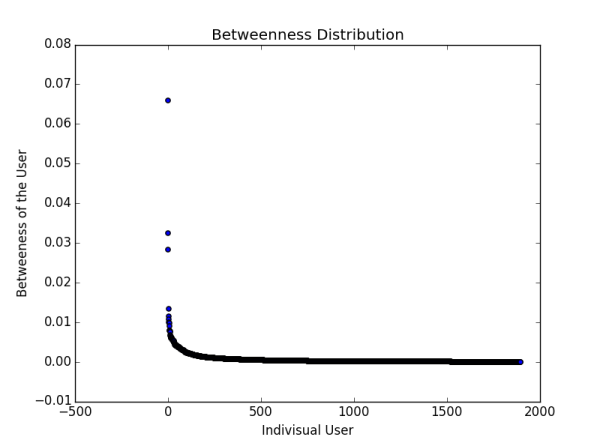
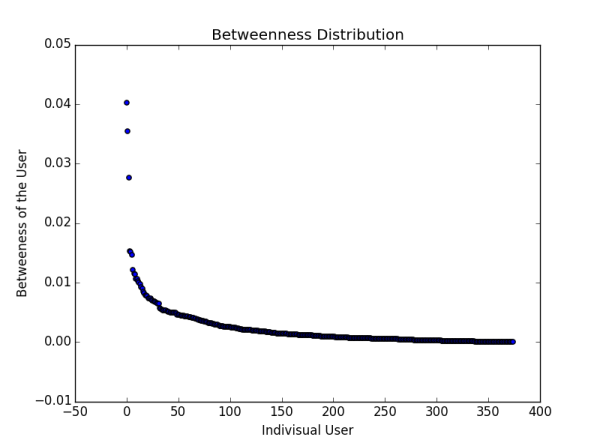
����Ŀ�����Ƿֱ������Net10k��Net10k�Ľ������ĶȺͽ������Ķȣ��������˷ֲ�ͼ���������ǵ�ʱ����Ƿ�ܣ�����Ľ������Ķ��ǻ��������Ӷ����������ӵģ�����Ϊ���岻�������ǿ������Լ���ע�����ˣ��Ӷ��õ�����Ľ������Ķȣ������Ա��ľ����Թ���������Ҫ˵һ�½������Ķȣ�����Net10k��Net50k�ķֲ�ͼ�ֱ����£�
�����ֵõ�������������β�͡�ͼ�к������ʾÿһ���ض��Ĵ�V���������Ǵ�V��Ӧ�Ľ������Ķȡ�������β�ͱ����ִ�V�Ľ������ĶȽӽ�0����ʹ��β����������������Զ�������ˣ����������Ķȵ�ֵ��Ȼ��С����˵��ʲô��˵����Щ��V��ʹ�˳�֪����Ҳ��������Ӱ��������V֮�佨����ע��ϵ��û���㣬�һ��������������·����������һ����V�����һ��˵��ʲô��˵����V�Ĺ�ע��������˽�׳ ����׳����ʹʧȥ�����㣬������Ȧ�ӵ���ͨ��������Ӱ�졣
�ٺ���Ƚ�һ��Net50k��Net10k�����Կ�����������Ȧ���������ɱ�ø�ǿ�����������㣬�ֵ��˽������Ķȶ���������0�� ���������ӽ�һ��ϡ���˴�����˵ġ������ԡ���ֱ���������ż����������Ȧ�ӣ���Net5k��Net1k����֪��ȫ���û������ֽ�׳��ֻ��Խ��Խǿ����Ȼ��������ȴ���ָ�����IJ��� �������������籾�����ԣ�ÿ���˼���ͬ����Ҫ ��Ҳͬ�Ȳ���Ҫ ����������Գ�֮Ϊ֪����ע���������е�һ�ֲ������еľ���ɡ�
2.5 ��V���ڹ�עʲô�����Ż������ ������dz�����һ�ֻ��֪�������Ż���İ취������Ŀ��Ψһ�漰���ݵķ���������ȡ��Net10k��Net50k��֧�伯��Dominant set��������������Ϊʵ���ϲ�������Ӽ����Ҳ�����������������ԾͲ�������������ˣ���Ȼ��ͳ�Ƽ����������û��Ļش�����Ӧ�������ǩ�����Ը��������ǩ�����ִ����������·ֱ��Ƕ��ߵ�ǰ20����
Top 20 from Net10k: ���������� 3792, ���� 3096, ��ʷ 1713, ���� 1464, ����ѧ 1432
Top 20 from Net50k: ���� 1435, ���������� 1365, ���� 1285, ��ʷ 1204, ��Ӱ 1084
�Ҹ�����Ϊ��V�ǻش����������Ӧ�Ļ��⣬�ܹ���һ���̶��Ϸ�ӳ��֪�����ƽ̨����Ļ����������ų̶� �����⣬�Ҿ���������ǰ��һЩ���Ż���Ҳ��һ���̶��Ͻ�����Ϊʲô��ͬ����Ĵ�V�ᱧ�ţ���Ϊ���۴���ʲôרҵ�������Ƕ��������ʷ����Ӱ�����ĺͷ����ֻ������ǻ����Ȥ�� ��һ��������Ȥ���ֶ��в����ļ���ͷ�������Ȼ������������ϧ��
���ˣ��������ڿ��Ի��Ͼ���ˣ���ӭ��������������ޣ����һ�������㷢�����ĵ��ź���ι�����ڴ˻�Ҫ��л����һ����뱾��Ŀ����������С��飬�ĸ���һ��ŵ����ڶ̶�ʱ�����������̶ֳȣ���Ŀreport�������ǵ���ϸ�ֹ�������л@egrcc ��zhihu-python��������ʡȥ��һ���������д��ʱ�䡣
������ظ�һ�飬�������Ҫ����һ������Щ�����Ļ����ϼ�����һЩ��Ȥ�ķ�����ͯЬ����һ����ϵ�ң�