|
Ŀ¼
���ǰ������(deep feedforward network):
����������(Convolutional Neural Network)
1���ṹ
1.1�������(input layer)
1.2��������(convolutional layer)
1.3������������(Rectified Linear Units layer, ReLU layer)
1.4���ػ���(pooling layer)
1.5��ȫ���Ӳ�(fully-connected layer)
1.6�������(output layer)
ѵ��������
һ����ʧ����:
1���ع�����
2����������
��������(Regularization)
1�����������ͷ�:
2����ǰ��ֹ(early stoping)
3��Dropout
4�����ݼ���ǿ
5��ע�������
6��ע������
7���Կ�ѵ��(adversarial training)
���������(Activation Functions)
1��Sigmoid
2��tanh
3��ReLU
4��Leaky ReLU
5��Maxout
6��ELU
�ġ�������һ��(Batch Normalization)
1�����
2��ǰ��
3������
�塢������ʼ��(Weight Initialization)
1����ʼ��ΪС�ı���̬�ֲ�
2����ʼ��Ϊ��ı���̬�ֲ�
3��Xavier ��ʼ��
�����ݶ��½�(Gradient Descent)
�̶�ѧϰ���㷨:
����Ӧѧϰ���㷨:
�����Ʒ���:
-
���ǰ������(deep feedforward network): -
1��ǰ������Ŀ��:�ǽ���ij������f(),������һ��ӳ��y=f(x;theta),����ѧϰ����theta��ֵ,ʹ���ܹ��õ���ѵĺ������ơ� ǰ��(feedforward )����Ϊģ�͵������ģ�ͱ���֮��û�з�������, ��ǰ�����类��չ�ɰ�����������ʱ,���DZ���Ϊѭ��������(recurrent neural network) -
����������(Convolutional Neural Network) -
������������һ��������������Ҿ�����Ƚṹ��ǰ�������� 1���ṹ  1.2��������(convolutional layer) ���������Ŀ������ȡ����IJ�ͬ����,��һ����������ֻ����ȡһЩ�ͼ����������Ե�������ͽǵȲ㼶,�����������ܴӵͼ������е�����ȡ�����ӵ������� ����Ұ(receptive field):ÿ��������Ԫ���ӵ����������С��r��Ԫ�ĸ���Ұ һ�������Ԫ�Ĵ�С����������������:depth, stride �� zero-padding�� ���(depth) : ����˼��,�����������Ԫ�����,Ҳ����filter�ĸ���,����ͬһ���������Ԫ����������:depth column ����(stride):��������ͬһ��ȵ���������������Ԫ,�����������ӵ���������ľ��롣���������С(���� stride = 1)�Ļ�,����������Ԫ������������ص����ֻ�ܶ�; �����ܴ����ص�������١� ����(zero-padding) : ���ǿ���ͨ�������뵥Ԫ��Χ�������ı����뵥Ԫ�����С,�Ӷ����������Ԫ�Ŀռ��С�� �����¹�ʽ����һ��ά��(�����)��һ�������Ԫ������м������ص�Ԫ:  W : ���뵥Ԫ�Ĵ�С(�����) F : ����Ұ(receptive field) S : ����(stride) P : ����(zero-padding)������ K : ���,�����Ԫ����� 

1.3������������(Rectified Linear Units layer, ReLU layer)
��һ���Ļ��Ի�����(Activation function)ʹ����������(Rectified Linear Units, ReLU)f(x)=max(0,x)
1.4���ػ���(pooling layer)
�ػ�(pool)���²���(downsamples),Ŀ����Ϊ�˼�������ͼ���ػ��㱣����ȴ�С���䡣
����:max pooling,�ػ����ģΪ2*2, ����Ϊ2

1.5��ȫ���Ӳ�(fully-connected layer)
ȫ���Ӳ���������Ƕ���ȡ���������з���������Եõ����,��ȫ���Ӳ㱾��������������������ȡ����,������ͼ�������еĸ߽��������ѧϰĿ�ꡣ

1.6�������(output layer)
����:��ʧ��������������Ͻ������ʵ���֮��IJ���
1���ع�����
1.1��L1������ʧ����(��С����ֵ���)

1.2��L2������ʧ����(��Сƽ�����)

2����������
2.1������֧����������ʧ Multiclass SVM Loss
SVM����ʧ������ҪSVM����ȷ�����ϵĵ÷�ʼ�ձȲ���ȷ�����ϵĵ÷ָ߳�һ���߽�ֵ �� ��
�����ȷ����÷ֱȲ���ȷ����÷ָ߳�,����ʧΪ0,����Ϊ:��ȷ����÷� - ����ȷ����÷� +
SVM������ʹ�õ�����Ҷ��ʧ(hinge loss),��ʱ���ֱ���Ϊ���߽���ʧ(max-margin loss)

��������:

2.2��Softmax Classifier (Multinomial Logistic Regression)(softmax������,��������ع�)
softmax����:
Softmax������ʹ�õ�����������ʧ(corss-entropy loss)

��������:

����:����ѧϰ��һ��������������Ʋ�����ѵ�������ϱ��ֺ�,���������������Ϸ����õ��㷨���ڻ���ѧϰ��,������Ա���ʽ����������ٲ������(���ܻ�������ѵ�����Ϊ����)����Щ���Ա�ͳ��Ϊ����(Regularization)��
1�����������ͷ�:

1.1��L1����

���L2����,L1���������ϡ��(sparse)�Ľ�(�˴���ϡ����ָ��������ֵ�е�һЩ����Ϊ0)����L1��������ϡ�������Ѿ����㷺����������ѡ��(feature selection)
1.2��L2����

ͨ����ΪȨ��˥��(weight decay)
1.3��L1��L2�����

2����ǰ��ֹ(early stoping)
��ѵ�����㹻�ı�ʾ�������������ϵĴ�ģ��ʱ,ѵ����������ʱ�����������,����֤���������ٴ�������
��ǰ��ֹ����:��ÿ����֤������½���ʱ��,���Ǵ���ģ�Ͳ����ĸ���;����֤���ϵ����������ָ����ѭ��������û�н�һ���½�ʱ,�㷨�ͻ���ֹ����ѵ���㷨��ֹʱ,���Ƿ��ش����ģ�Ͳ�����
�ŵ���:��Ч�Ժͼ���
3��Dropout
��ÿ��ǰ����,�����һЩ��Ԫ���������0,���ư����Ƕ����������ı�����һ�������������ز�һ����0.5(������0.5),�����һ����0.2(������0.8).
�ŵ���:1�����㷽�� 2������ô�������õ�ģ�ͻ�ѵ������,����������ʹ�÷ֲ�ʽ��ʾ�ҿ���������ݶ��½�ѵ����ģ���϶����ֺܺá�����ǰ�������硢�������������Լ�ѭ��������
ȱ��:1��ֻ�м��ٵ�ѵ����������ʱ,Dropout�������Ч 2����������δ��������ݿ���ʱ,�ල����ѧϰҲ��Dropout�������ơ�
4�����ݼ���ǿ
�û���ѧϰģ�ͷ����ø��õ���ð취��ʹ�ø�������ݽ���ѵ�������ǿ��Դ����˹����ݲ����ӵ�ѵ�����С�
��������Է���Ķ���ʶ���������Ч�����ǿ��Զ�ԭʼͼƬ���з�ת����ת������ü�����,ɫ�ʶ���������µ�ͼƬ���ݡ�
5��ע�������
��ѵ���м���һЩ�����,�ڲ��ԵĹ�����ʹ��һЩ����ȫ�ֹ��Ƶ������������������ԡ�
����:Batch Normalization
6��ע������
����������������,��Ϊ���ݼ���ǿ���ԡ�
���������������ص�Ԫ,����:Dropout��Stochastic Depth��Fractional Max Pooling
������������Ȩ��(weight),�������Ҫ����ѭ�������硣����:DropConnect
���������������,����:��ǩƽ��(label smoothing)
7���Կ�ѵ��(adversarial training)
�Կ�����(adversarial example):����۲��߲�����ԭʼ�����ͶԿ�����֮��IJ���,��������������dz���ͬ��Ԥ�⡣
�Կ�ѵ��:�ѶԿ����������µ�ѵ���������뵽ѵ������,ԭʼ�������϶Կ�����һ��ѵ����
-
���������(Activation Functions)
1��Sigmoid


�ŵ�:1�����������Χ(0,1)
2����ǰ�Ƚ�����,��Ϊ����ѧ�Ͽ��Խ��ƿ�����һ����Ԫ�ı��ͷŵ���
ȱ��:1�����͵IJ��ֻ�����ݶ���ʧ
2�����������0Ϊ���ĵĶԳ�
3��exp()ָ�������ʱ��
2��tanh

�ŵ�:1�����������Χ(-1,1),��0Ϊ���ĶԳ�
ȱ��:1�����͵IJ��ֻ�����ݶ���ʧ
3��ReLU


�ŵ�:1�����������ᱥ��(��������ݶ���ʧ)
2������Ч�ʸ�
3����Sigmoid/tanh�����ø���(����ֵ:��6������)
4��������ѧ�ϵĽ��ͱ�Sigmoid������Щ
ȱ��:1��������0Ϊ���ĶԳ�
2��һЩReLU��Ԫ�ᡰ�ҵ���
4��Leaky ReLU
 PReLU: PReLU: 
�ŵ�:1��ӵ��ReLU�������ŵ�
2�����ᡰ�ҵ���
ȱ��:1��������0Ϊ���ĶԳ�
5��Maxout

�ŵ�:1��������
2���ۺ���ReLU��Leaky ReLU
3�����ᱥ��(��������ݶ���ʧ),���ᡰ�ҵ���
ȱ��:1�������ӱ���
2��������0Ϊ���ĶԳ�
6��ELU

�ŵ�:1��ӵ��ReLU�������ŵ�
2�����ӽ���0Ϊ���ĶԳ�
3����Leaky ReLU���,�����������˶�������³����
ȱ��:1��exp()ָ�������ʱ��
-
�ġ�������һ��(Batch Normalization)
1�����
Batch Normalization(������һ��)��2015�������,���ĵ�ַ��
����ѧϰ��������������ֵΪ0,��λ����IJ�����������ɵ�ʱ���������ֵø���,�����������ѵ��,ÿ���weight�ڲ��ϸ���,���º���layer���������ݻᷢ��ƫ��,���پ��о�ֵΪ0��λ����,�����ݽ�������ǰ,��������Ԥ�����������������⡣���������Batch Normalization��
λ��:������һ��ͨ����ȫ���Ӳ�(fully-connected layer)�������(convolutional layer)֮��,����������(ReLU layer)֮ǰ

�ŵ�:1������ʹ�ø��ߵ�ѧϰ��
2�����ٶԲ�����ʼ��������
3���߱����Ĺ���,һ��ʹ����BN,�Ͳ���ʹ��Dropout
4�������ݶ���
2��ǰ��
2.1��ѵ��ʱ,����ÿ��batch���й�һ��, �� �� �ǿ�ѧϰ���� �ǿ�ѧϰ����

2.2������ʱ,ʹ�ù̶���ȫ�ֵ� �� �� (ѵ��ʱ�ռ��������о�ֵ) (ѵ��ʱ�ռ��������о�ֵ)
2.3����ʽ:

��������:
if mode == "train":
sample_mean = x.mean(axis=0)
sample_var = x.var(axis=0)
sample_x = (x - sample_mean) / (np.sqrt(sample_var + eps))
out = gamma * sample_x + beta
running_mean = momentum * running_mean + (1 - momentum) * sample_mean
running_var = momentum * running_var + (1 - momentum) * sample_var
elif mode == "test":
sample_x = (x - running_mean) / (np.sqrt(running_var + eps))
out = gamma * sample_x + beta
3������
��ʽ:

��������:
m = x.shape[0]
dgamma = np.sum((dout * sample_x),axis=0)
dbeta = np.sum(dout,axis=0)
dsample_x = dout * gamma
dvar = np.sum(dsample_x*(x-sample_mean)*(-0.5)*np.power(sample_var+eps,-1.5), axis=0)
dmean = np.sum((dsample_x/-np.power(sample_var+eps,0.5)) + dvar*np.mean(-2*(x-sample_mean)),axis=0)
dx = dsample_x/np.power(sample_var+eps,0.5) + dvar*2*(x-sample_mean)/m + dmean/m
-
�塢������ʼ��(Weight Initialization)
1����ʼ��ΪС�ı���̬�ֲ�

�����������,
���Ƕ��ڸ���������������:��Ϊÿ�γ˵�W����С,�ᵼ��ÿ������Խ��ԽС,������0������ʱ,�ݶ�Ҳ��������0.
2����ʼ��Ϊ��ı���̬�ֲ�

���W�ᵼ���������,������������������(ReLU layer)ʱ�ᱥ��,�����1��-1,�����ݶȶ�Ϊ0(�ݶ���ʧ)
3��Xavier ��ʼ��

��ʼ��Ч������,���Ǽ����ΪReLUʱ���ֲ��á���ΪReLUÿ�μ�����kill��һ��ĵ�Ԫ,�����ʽÿ�γ��ԵĻ���ȫ����Ԫ�ķ���,�ĺ�Ĺ�ʽ����,������ʹ��ReLUʱҲ���ֲ�����

-
�����ݶ��½�(Gradient Descent)
�̶�ѧϰ���㷨:
1�������ݶ��½�(Batch Gradient Descent)
BGD ÿһ�ε�����������ѵ���������������� cost function �Բ������ݶ�,���Լ������������,�ر����������ܴ��ʱ��,�������ܴ�,���Ҷ��ڴ�����Ҳ��Ҫ��(mΪ��������,nΪ�����ܴ���):

����:BGD������������������ȫ�ּ�Сֵ,���ڷ����������������ֲ���Сֵ
2��С�����ݶ��½�(Mini-Batch Gradient Descent)
�� SGD ��������ÿһ��ѭ������������ÿ������,���Ǿ��� b ������������(mΪ��������,b��ÿһ������������)��

����:MBGD ÿһ������һС������,�� b ���������м���,���������Խ��Ͳ�������ʱ�ķ���,�������ȶ�,��һ������Գ�ֵ��������ѧϰ���и߶��Ż��ľ�����������и���Ч���ݶȼ��㡣
3.������ݶ��½�(Stochastic Gradient Descent)
��BGD ��һ�ε������������ݼ����ݶ����,SGD ÿ�ε���ʱ��ÿ�����������ݶȸ��¡�1���Ƚ�ѵ�������������˳�� 2���ظ�m�ε���,ÿ��ʹ��һ��ѵ������������cost fuction�Բ������ݶȡ�(mΪ��������)

����:1����Ϊÿ��ֻʹ��һ���������и���,���Ի���� cost function �����ص���
2��SGD��������BGDҪ��,ʹ��SGD������ÿ�ε����������������Ż�����������Ȼѵ���ٶȿ�,����ȷ���½�,������ȫ�����š���Ȼ����һ���������,���Ǵ�����������,���ǵ�����ȷ�ĵ����ġ�
�ݶ��½�����������:�ֲ���Сֵ�Ͱ���
���������ط�,�ݶ�Ϊ0,�ᵼ���ݶ��½��㷨�������һ����˵��������ձ�,�ر����ڸ�ά�ռ䡣
���:ʹ�ô��������ݶ��½��㷨���Ժܺõش����ֲ���Сֵ�Ͱ��������

4������ݶ��½�+������(SGD + Momentum)

֮ǰ�IJ������ݶ�(dx)*ѧϰ��(learning_rate),���ڵIJ������ٶ�(vx)*ѧϰ��(learning_rate)��
�ٶ�(vx)=Ħ��ϵ��(rho)*�ٶ�(vx)+�ݶ�(dx)
���϶����ĺô�:1������˾ֲ���Сֵ�Ͱ��������,����Щ������Ȼ�����ٶ�,���Լ�ʹ�ݶ�Ϊ0,����������Ϊ0
2�����϶����Ժ�,�ӿ����½����ٶ�,�ɴ˼ӿ���ѧϰ���ٶ� (��ɫ����:SGD,��ɫ����:SGD+Momentum)

5������ݶ��½�+Nesterov ����(SGD + Nesterov Momentum)
�����Ƚ�:

Nesterov�����ͱ�����֮��������������ݶȼ�����,Nesterov������,�ݶȼ������ʩ�ӵ�ǰ�ٶ�֮��(��ͼ����)�����,Nesterov�������Խ���Ϊ��������������������һ��У�����ӡ�
�������ݶȵ������,Nesterov������������������ʴ�O(1/k)(k����)�Ľ���O(1/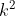 )����ϧ,������ݶȵ������,Nesterov����û�иĽ������ʡ� )����ϧ,������ݶȵ������,Nesterov����û�иĽ������ʡ�


����Ӧѧϰ���㷨:
ѧϰ�����������õij�����֮һ,��Ϊ����ģ�͵�������������Ӱ�졣
1��AdaGrad

����ʱ������,grad_squared���ۻ�Խ��Խ��,�ɴ˲�����Խ��ԽС��
����������˵,�ڼ�ֵ����Χ��������������,������ʰ����������õ�����
���ڷ�������˵,�ھ����ֲ���ֵ��ʱ,���ܻῨ�����
2��RMSProp

decay_rateͨ����0.9��0.99
RMSProp�е�����ݶȵ�ƽ�����϶���,ʹ�䲻�Ῠ�ھֲ���ֵ�㡣����RMSProp�ڷ������ϱ��ֵø��á�

3��Adam

Bias����������һ��ʼ���ֺܴ�IJ���
Adam�е���RMSProp�Ͷ����Ľ��,ͨ���Գ�������ѡ���൱³��,�ʺ���Ĭ���㷨��

�����Ʒ���:
����������
| 





