����Ŀǰ���ڿ����Ļز�����ʹ�õ�Ҳ��python������Ҳ�ڽ������ܷ�����Ż������½��鹩�ο���
1. �ڶ����Ż�֮ǰ����profile����������ʱ�䶼������Щ�ط���:
python -m cProfile -o output.prof your_program
����֮���һ����������ڣ��úÿ�������Щ������ʱ��࣬��ʱ����Ϊ���ô���̫���أ�������Ϊ���ε��ú�ʱ������ȷ�Ż��ص㣻
2. �����ظ����㣬��������������� functools.lru_cache��
3. ����list comprehension�ĵط�����Ҫ��for������numpy�ĵط�����Ҫ��дѭ������Ҫ��pandas��
4. ����Ļز⣬40w��tick�Ļ��������������Ӧ����ֱ��load���ڴ���İɣ�
5. �������Ļ�����Numba �� Numba�����ǰ�װ�鷳һЩ��ʹ�������dz����㣬�ٶ����һ����������û���⣻
6. ������õİ�PyPy��֧�ֵĻ�������pypy��
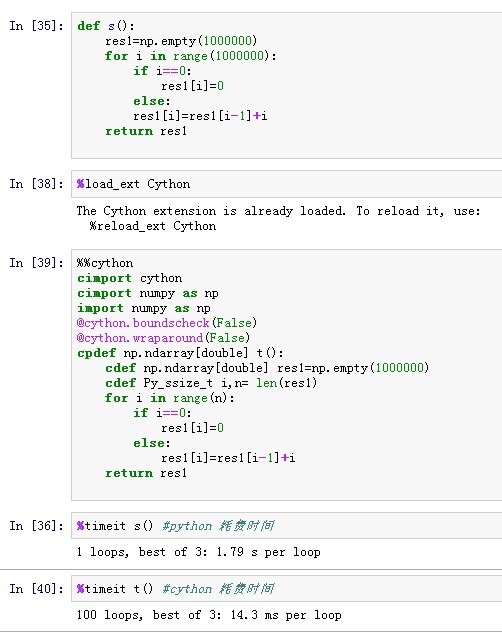
7. Cython��c module������Ķ�ûЧ���Ļ�����������ĺ�ѡ�����ˡ�
----------------
���ʱ�䣺
����Ŀǰ�������ˣ���ӭ��λͶ����
Ricequant - Beta |