����2������˹�ٴ�ѧ����Ϣ�����������ģ�CITP���ͱ����������ݴ�ѧ����ɽ��У��University of North Carolina at Chapel Hill����2013�귢����һƪ���¡�Big Data: Pitfalls, Methods and Concepts for an Emergent Field�������ݣ�һ��������������塢���������ͨ��ʵ���һЩ�г�Ӫ����Ա�������棺������ȷ�ϳ����ķ����Ƿ��ܹ������ظ��ǵ������г�����Ҫ�Դ��罻ý����������Twitter��Facebook���ռ������������ݹ������š�
1.Inadequate attention to the implicit and explicit structural biases of the platform(s) most frequently used to generate datasets (the model organism problem).
2.The common practice of selecting on the dependent variable without corresponding attention to the complications of this path.
3.Lack of clarity with regard to sampling, universe and representativeness (the denominator problem).
4.Most big data analyses come from a single platform (hence missing the ecology of information flows).
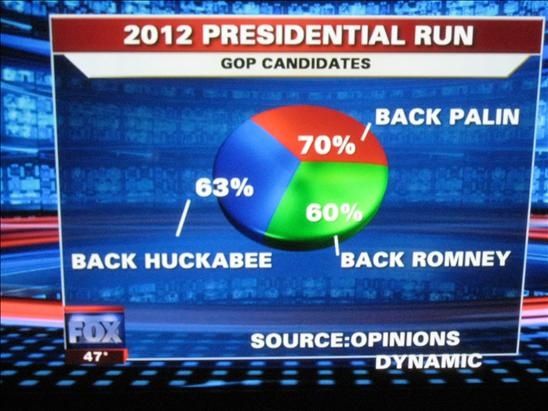
��������������ĺͻ���ʱ����������ĺܻ������������۸�ûѧ��ͳ��ѧ��ͬѧ�ġ�David S. Moore�ڡ�ͳ��ѧ�����硷���ᵽ��������������鲻���ṩȷ�غ����õĽ�����ر�����Щ�����Ӱ�졢�����Ǽ�¼��������� (especially those designed to influence public opinion rather than just record it����˵�ľ����㱨�ɣ�
David S. Moore�ڡ�ͳ��ѧ�����硷�������һ������Ը��Ӧ���������ӣ�ר������Ann Landers�ڱ�ֽ�Ϻ�������߾͡������ܹ���������Ը����ҪС���𣿡�����ͶƱ�����յ������Ż�Ӧ�У�70%�Ĵ��ǡ�No��������Щ���Ż������˴������µĹ��£�������ĸ��κ�����ࡢ��Ů��α������塣
��¼2������ij������������ǰ���ʵ����� Questions to ask before you believe a poll
��������ʹ�úõ�ͳ�Ƽ��ɣ���һ�������������ij�����ע�����ʵĴ�ǣ�������Ӧ�����������ȷʵ�����ṩȷ���м�ֵ����Ϣ�������������������鲻���ṩȷ�غ����õĽ�� (especially those designed to influence public opinion rather than just record it)��Ϊ�ˣ���������עij������������֮ǰ���б�Ҫ���ʼ������� ��
˭���ĵ���(Who carried out the survey)������������õ���ϰ�ߵ�רҵ����������ֵ��������
������ʲô(What was the population)�������뷴ӳ���������
�������ѡ��(How was the sample selected)�������з��ἰ���������
���ö�������(How large was the sample)�� ���������ṩ�����������Ŷȡ�
��Ӧ�ʶ��(What was the response rate)��������Ӧ��no response��ͬ���ܴ�����ƫ��
����뱻���������нӴ�(How were the subjects/units contacted)��������ͬ����ϵ��ʽ������桢�绰��̸�ȣ�Ӱ�쵽��Ӧ�ʡ��ش����ʵ�ԡ�����ijɱ���
�з���ͻ���¼�Ӱ��(Was it just after some event which might have influenced opinion)�������Ƿ���ij����Ӱ��������·���֮��ͽ��е��飿
���ʵľ�����(What were the exact questions asked)��������������յ��Եġ���������(loaded question)"?
��һ����˵����������Ů����˵�����������谮��������к�������������Ů������Ȼ��������˰����������Ц������������谮����������˿�ѵ���Ҫ�������в�Ů���ˣ� ���ǣ�������������ʳ�����Ӱ�쵽���ӵ��Ա��� 2008�꣬��Ȩ����־��Ӣ���ʼ�ѧ��ѧ�����Ϸ�����һƪ���£���You are what your mother eats: evidence for maternal preconception diet influencing foetal sex in humans�����о���Ա�ʹ���ش���������⡣����ͨ����740��Ů�Խ��з����о�������������ǰ�������ڡ��������ڵ���ʳ�������̥���Ա��Ӱ�졣�о���Ա��133��ʳ������ʾ������о���������֣�����ǰ�緹�Ը��������Ů�ԣ����������к��������������������ʳ�ﶼ����Ů�Ա�û�����Թ����� ��ƪ����һ��������������㷺��ע��Google�������50000��Ҫ֪���������һƪ��ѧ�����ף�Ҳ���������֮�ߵĵ������ ��˸ߵĹ�ע�ȣ���Ȼ�Ӳ���ѧ��������ɡ�2009�꣬ͬ���ڡ�Ӣ���ʼ�ѧ��ѧ�����ϣ�һƪ�����Ե��������·�����������Cereal-induced gender selection? Most likely a multiple testing false positive����������ɵģ�����λͳ��ѧ�ң�Stanley Young��Heejung Bang��Kutluk Oktay������Ʋ��ʵ������е����ݻ�ȡ�����⣬�������ƫ�С���������ȷ�����������Եȵȣ�ֱ�����ǰһƪ���µ�ͳ��ѧ����������ɡ������ڶ�ǰһƪ�������ṩ��ԭʼ���ݽ�������ͳ��֮���֣���Щ������ʵȫ��û������ԣ������ó��ġ����������к����Ľ��ۣ���ʵֻ��һ��żȻ�¼��� Ҳ����˵��֮ǰ�о�����133��ʳ�����������Ů��Ӱ�춼������ֲ��ģ���������һ���о���ʱ��ǡ�÷�����һ���о��������������������к����ⴿ������żȻ�¼�����ƪ���°�һ��żȻ�¼��������۱��������ˡ�