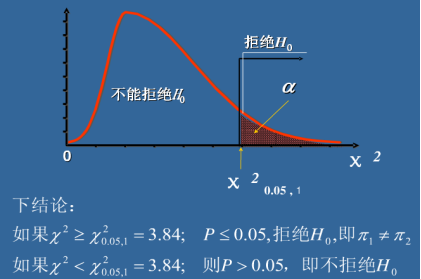
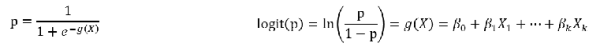����ڴ�ͳ��أ������ݷ���ڽ�ģԭ���ͷ������ϲ��ޱ�������ֻ������ͨ���������ĺ������ɼ�������ά�����ݱ�����ͨ���������ݵ����������ǿ���������ͳ��ǿ�����ϵ��
��ģԭ���ͷ������ϲ��ޱ������� �����ݷ�ؼ������ݷ��տ��ƣ���ָͨ�����ô����ݹ���ģ�͵ķ����Խ���˽��з��տ��ƺͷ�����ʾ��
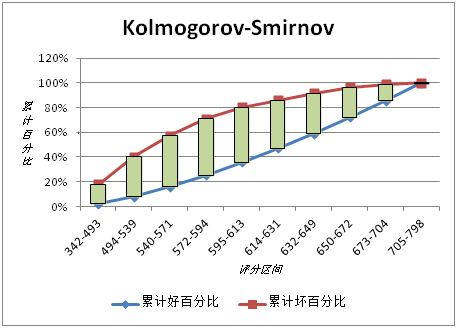
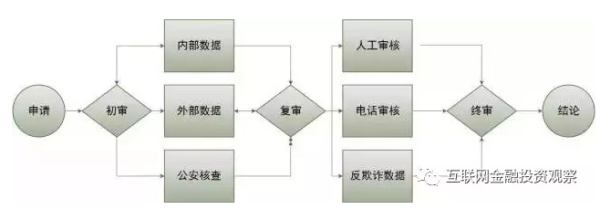
Ҫ��������ݷ�أ�����Ҫ�Ѵ�ͳ���ڷ�ظ���������������е����ÿ�����Ϊ���� ����һ�´�ͳ���е������������̡�����ͼ�ۺ��˼����������ÿ����ĵ�������̣�
���ÿ���˼�������ͼ
�������Ͽ������е�������ˣ����Է�����ֿ�ģ�͵��Զ����Ϊ�������˹����Ϊ����ģʽ������Ҫ�ض���˵Ļ������˹����У�������֤��Ĺ�����У������ϵ�˵���ʵ�Եȡ���Ҳ��Ϊʲô����ʵ������һ�����������ÿ���������л��յ��˹���˵绰��һ�����˲�����Ҫ����֤���ڼ��ɻ�����ÿ���
����������Ͽ�������������˵��Ӱ��������ȵ���Ҫ���ذ����ͻ�����������������Ů�����䡢�����̶ȵȵȣ����ͻ��ķ��ձ�¶�����������롢ծ���������ծ�����ۺ������������е������֣�������������������������ÿ�ʹ������ȣ���
���������ʻ����������У����¶���ѭ������һ����������������˵������Ա�֮�£��Ϳ��Կ�����ʱ�»��������ڹĴ��Ĵ����ݷ����ԭ���ͷ������ϸ���ͳ���ڵķ��տ��Ʋ�û�б�������
�г��հ������ �������������������ϵ �����ݷ������ڴ�ͳ�����˵����ģ��ʽ��ԭ����ʵ��һ���ģ�������Dz��������ø���ά�����ݣ�����������㼣�����ഫͳ����û�д����������ݡ�
������̵���ҳ������ͻ���app����Ϊ�켣������GPS��λ����Ϣ�ȣ���Щ��Ϣ���ƺ�һ���ͻ��Ƿ����ΥԼû��ֱ�ӹ�ϵ����ʵ��ͨ�������������ۻ����ܹ��������dz���Ч��ʶ��ͻ���������
�����ݷ���봫ͳ���з�صıȽ�
���������Ǵ����ݷ��һֱ�����Ļ������ƣ����ڶ��ٵ�����������������ϴ�ҵ��һֱû��ͳһ���߽�Ϊͨ�õı��� ���ݹ������ϣ����Ͻ���ķ�غ���CTU Ͷ����2200��̨��������ר�����ڷ��յļ�⡢�����ʹ��á��»����ı�����ʾ�����Ͻ��ÿ�촦��2�������ݣ�����ά����10��������������2016��6�£�Ͷ���������Ĵ����ݹ�˾ZestFinance��֮���������Ϸ�������˺��ʹ�˾ZRobot��ZRobot��Ҫ��λ��Ϊ������ҵ�ṩ���ݽ�ģ���������֡��ʲ����ۡ���թʶ��ȷ��������������й����ĵ���-���������������ڹ������������ӵ���ߡ�
�����ʱ��ϻ��˽��Ϸ����ʾ�����ջ��ո��ܲ��ἰ�Ĵ����ݸ��ȫ��������������ν�Ĵ�����Ӧ�õĹ�˾������50�ҡ������Ĺ�˾ֻ���������ݵ��Ż����������ܳ�֮Ϊ�����ݷ�ء�
������ά������㼶����ͳ���ڷ�غʹ����ݷ�ػ���һ���������������ڴ�ͳ�������ݺͷǴ�ͳ�������ݵ�Ӧ�á� ��ͳ�Ľ������ݰ��������������ἰ�ĸ���������������롢�������ȵȡ�������˾�Ĵ����ݷ�أ������˴����ķǴ�ͳ�������ݡ����簢��Ͱ͵�������¼�����������Ѽ�¼�ȵȡ�
���������ϣ���ǿ��ǿ�����ϵ������ͳ��ѧ�ϵ�������Ǵ����ݷ�������ڴ�ͳ���ڷ�صĵ��������� ��ͳ���ڻ���ǿ�������������������֮�������������ܹ���ͨ�����һλ��Ը������ǰ���������ÿ����ĸ����˱�ʾ�������е����������У����Ǽ��㷢����һЩ�Ǵ�ͳ������ͳ���Ͽ�������˽������ij������ԣ�������ܹ������Ͻ�ͨ������Ҳ��Ȼ������á�
���������Ƿ�����ij��ʱ���������Ŀͻ����Ӻ������ݱ������������ڵĸ��ʾ��DZȽϸߡ������û�취�����Ͻ���ͨ���еĵ����������Dz���óȻ������Ϊ������������ģ�͵���ȥ�ġ���
���봫ͳ���ڻ�����ͬ����������Ĵ����ݷ�����յ����Ǵ�����DZ����������ݡ�Ϊ��˵��DZ�ڣ���Ϊͨ���������ķ�ʽץȡ��������֮��һ������һ�����ݷ�����ɸѡ�Ĺ��̣�����������У��������ݻᱻ֤�������ֱ�ӱ��ߵ������µ���������ݲŻᱻ���õ�������˵���ȥ��
��ͳ������С����˾�ڷŴ������У�����һЩ�Լ��ľ����жϣ������һЩ�ض���Ϊ����������ϰ�ߵĿͻ���������һ���Լ���ֱ�۴���жϣ���Щ�dz��ھ����ۻ��Ľ��������һЩ����˾����ͨ�����������ֶΰ���ЩҲ�������������뵽�����˵���ȥ��
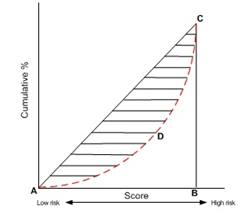
�����ݷ����Ҫ����Ǵ�ͳ�������������˵������ϵ�ſ�����ع�ϵ������ҵ��ԭ��ġ������Ż��������ڵĻ��ȣ������ݷ�������¡��й��Ļ��������ڣ�����Ŀ�Ⱥ����֮���Է�Ϊ���ࣺ���Ŵ���ʷ��¼�ߺͲ��Ŵ���ʷ��¼�ߡ�������������Ⱥ��ǡǡ���й���ͳ���ڻ���û�з�����������Ⱥ��
����������Ⱥ�����й���ѧ�������졢�Լ�һ���ֵİ���ȡ��ⲿ�ֿ�Ⱥ��������û�����ű��棬����û�й������ڷ����¼���հᴫͳ���ڵķ�����˻����ˮ��������״����
�Դ�ͳ���ڻ������ѣ��ڶ�һ���ͻ��������÷�������ʱ��������λ��ǿ��������ֱ�ӹ�ϵ�������籣��¼������һ��û�й̶������Ŀͻ�������������λ�ͱ����һ�����������������ķ������������ޡ�
ͬ����ѧ������ס�ء������¼��Щ��ͳ��ǿ���ڷ��ָ�������������Ŵ���¼�ߺͲ��Ŵ���¼��ʱ��������ͬ�������⡣����ʹ����˾��Ҫͨ��������ʽ�����µķ��������Դ��������֤��Щ���ݵ���Ч�ԡ�
������ɱ���� �����ݷ����Ч���д���֤ ����ڴ�ͳ���ڻ���������˾�����˷Ǵ�ͳ���ݻ�ȡ��;���������¿ͻ�Ⱥ��ķ��ն��ۣ���һ�ַ������ݵIJ��䡣����Щ���ݵĽ��������ж�ǿ����Ȼ�д���֤��
�����ݵĽ�������ȡ�������ȥ�ھ��義�������Ϲ����¼��ʵ��Ŀ���Ⱥ�ܺõĿ̻����ͻ��ĵ�ַ��GPS����פ���ĵ�ַ�ȣ���һ���˵ľ�ס�صĸ��ʺܴ�����һ���ϣ���Ѷ�������С��������ڣ����Ͻ���Ȼ�������ͷ���ж������ź��������ݡ�
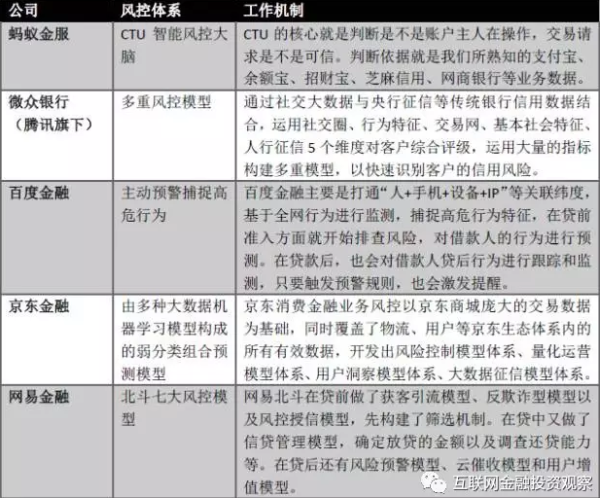
����˾�ķ����ϵ ��Դ���������繫����������
���ݡ�֤ȯ�ձ������������������������ĵ��ʾ���������1��Ԫ�������ʵ���0.3%�����ڿ����õ���Ѷ�����ݣ������������й�˾û���ȵģ���С�����������ǵ�����̫�����ˡ���ǰ����Ը������ʿ¶��
��ͷ�������ԣ�����˾����������㵽�������¸��ֳ���������������ҵ��˾��·�ѱ��������ڻ�������ͷ��δ�漰������С�����ܣ��Ⱦ�ͷ����������������õ����ݣ������Ż��Լ�������Ӧ����������Ϊ��ҵ��˾ɱ����Χ��һ��·����
��һ���ȶ��ij������ܹ�����Ȼ״̬����ʵ�زɼ����ͻ���Ϊ��չ�ֵ����ݣ����Ǵ����ݷ�ص�ǰ�ᡣ��һЩ��δ����ͷ�ᵽ�ij�����������ɱ�Ѿ��dz����ҡ�
ũ���ڡ�����ڡ���˾��ⷿ�������ʷ��ڡ�ѧ�ô��������С�Ȥ���ڡ������֡��������ŷ��ڡ�������������ũҵ���ⷿ�����졢ѧ�������εȸ��������Ͳ�ͬ��Ⱥ�µ������Ѿ��������Ȼ���
½����CEO�ƿ�����2016����й�֧�������뻥����������̳������½�������껪��������5%����6%�����ң�������Ѷ�ƾ��ı������ƿ���ָ���������������ã�P2P����ҵ�����ʽ�Զ��10%�������¾���100�˵ı�����ѧ��������ҵķ����ֻ����ʵ���1%�������������ʾ��2016��������ȣ��ҹ�������ҵ���еIJ���������Ϊ1.67%��
���ڽ���11�£���21���;��ñ�������¶���������ѽ��ڹ�˾�Ĵ�����ʸߴ�10.37%��������ָ���������ڲ���ʿ¶��10.37%�Ļ��˾��Բ�����ҵ��ߵģ��ܶ������ѧ���ṩ�������ѵ�ƽ̨�������ʳ���25%��
�����ʡ������ʡ������ʣ����ֲ�ͬ��ָ�����ھ���ͬ��������ྶͥ��ȱ��ͳһ����ҵ����Ұ��������Ҳ��������Ź�����ͻ���֮�ӡ�������ҵ�Ļ�����һ��������ɴ��Ů�ɣ�ʼ�ղ��������ݡ�
��ͬ��Ⱥ�Ļ��˱��������ݶȲ��죬�������õ����ݻ�ȡ������Ӧ���������ܻ���һ���̶����Ż����ֱ��֣���Ϊ��ҵ��һ���������Ǻӣ���Ҳ��������ҵ��˾��һ�����ᡣ
���ڵĴ����ݷ������ �������й�������ϵ�IJ����ơ� Ҫ֪�������ݷ�صĵ�һ�����ǻ�ȡ���ݡ���ʿ����ѯ�ı�����ʾ�����и������ż�¼�����ʽ���Ϊ35%����������ҵ��Ŀ���û�Ҳ��Ϊ���ÿ����������Ⱥ�������֪�������˾�û��ʲô���ü�¼�����ˡ����������ѽ��ڹ�˾����������������Ժ�С�����ڴ������˾�������ǽ��Լ������ݹ��������������Ż������ٴ����Ż��������ȡ���ݣ����������ݵ���Ч�Դ��ɡ���ȡ�������ݻ�����Ϊ�ܶ˾�����Լ��Ĵ����ݷ��ģ�͵ĵ�һ�����⡣
������й���������թ���� ǰCapital One�߹ܣ�����Ȥ��CRO��ճ�F��Ůʿ�ͱ�ʾ����Ŀǰ���ڵ������г�������թ��Ȼ��ͷ�����⡱�����й���������թ��������������һ����ҵ�������н鹫˾���̼��������Լҹ�˾�����ۣ����һ����ͨ�����ַ�ʽ�ټ�������ʶ�������û������н�����ٽ��赽��Ǯ�Ϸ֡���թƭ������·�����Լ����ڶ�ѹ�����û���ͷ�ϡ�
Ȼ��ǰ����������û��õĶ�����ʵ����Ϣ��ƽ̨���û��Ķ��Ҳ�ں����ķ�Χ�ڣ�������թƭ��ʽ��ƽ̨���ںܱ����Ĵ��������ڵĴ�����ʽֻ���Ƿ���һ���ץһ�𣬷���֮�������ٶ��ǹؼ�������ճ�F��ŮʿҲ��ʾ֮�����ø������ķ�ʽ����������Ŀǰ���������Ѽ������Լ���ͬ������������ذ�����Ѱ���ⲿ�����ױ����õ���Ⱥ���ϵĹ��ԡ������㹻�������Ժ����ǿ�����������Щ�û��Ļ���������صķ��ģ�͡���
������������ǽ�����ҵƵ���ġ�����족�¼��� �������ݱ�������������һ����Ҫԭ�������Ϊ��������Ч�����ݼ�Ԥ��δ��������������ͳ��ѧ����֮�ϵĴ����ݿ���Ԥ�����������֮��ĺ�����¼��𣿿��º��ѡ��ڹ��ڴ����ݷ�صķ�չ���������˼����ʱ�䣬�����ڼ��й���δ����������2008�������δ�Σ���Ĵ��ģ����Σ������ˣ����ڴֹ�˾�����Ĵ����ݷ����ϵû�о��������˾��û�����ѹ�����ԣ���ʱ������ȫʧ�顣
�������ˣ���ʵ�����ˣ����Ե�չ�֣�������ģ����Ȼ�������Ǵ������ԣ������ڽ��ڵķ�أ���Щǰ���DZ�Ҫ�ģ�
1 ��Щ�������ݱ����ǿͻ���Ȼ��Ϊ����¶��չ�֣��������ܱ�������ѡ�����ݲ���Ч��
2 �ɼ��Ĺ����ȶ����ɳ����������ų��á�
3 ���ݹ�һ����ȣ��������������á�
���ڵİ�����Ѷ���������ڴ����ݷ�ض�������һЩ�ص㡣