Դ�����
HashMap ����һ����ν�ġ�Hash �㷨��������ÿ��Ԫ�صĴ洢λ�á�������ִ�� map.put(String,Obect)���� ʱ,ϵͳ������String�� hashCode() �����õ��� hashCode ֵ����ÿ�� Java ������ hashCode() ����,����ͨ���÷���������� hashCode ֵ���õ��������� hashCode ֵ֮��,ϵͳ����ݸ� hashCode ֵ��������Ԫ�صĴ洢λ�á�Դ������:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public
V put(K key, V value) {
if
(key ==
null
)
return
putForNullKey(value);
int
hash = hash(key.hashCode());
int
i = indexFor(hash, table.length);
for
(Entry<K,V> e = table[i]; e !=
null
; e = e.next) {
Object k;
if
(e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
return
oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return
null
;
}
|
��ϵͳ�����洢 HashMap �е� key-value ��ʱ,��ȫû�п��� Entry �е� value,����ֻ�Ǹ��� key �����㲢����ÿ�� Entry �Ĵ洢λ�á���Ҳ˵����ǰ��Ľ���:������ȫ���� Map �����е� value ���� key �ĸ���,��ϵͳ������ key �Ĵ洢λ��֮��,value ��֮���������T��

������
Hashmap�����bucket�����˵���������ʽ,ɢ�б�Ҫ�����һ���������ɢ��ֵ�ij�ͻ����,ͨ�������ַ���:�������Ϳ��ŵ�ַ�������������ǽ���ͬhashֵ�Ķ�����֯��һ����������hashֵ��Ӧ�IJ�λ;���ŵ�ַ����ͨ��һ��̽���㷨,��ij����λ�Ѿ���ռ�ݵ�����¼���������һ������ʹ�õIJ�λ��java.util.HashMap���õ��������ķ�ʽ,�����ǵ����������γɵ������ĺ��Ĵ�������:
|
1
2
3
4
5
6
|
void
addEntry(
int
hash, K key, V value,
int
bucketIndex) {
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] =
new
Entry<K,V>(hash, key, value, e);
if
(size++ >= threshold)
resize(
2
* table.length);
}
|
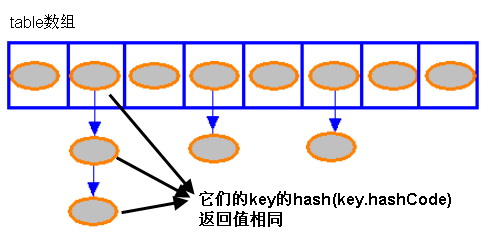
���淽���Ĵ���ܼ�,�����а�����һ�����:ϵͳ���ǽ������ӵ� Entry ������� table ����� bucketIndex ������������� bucketIndex �������Ѿ�����һ�� Entry ����,�������ӵ� Entry ����ָ��ԭ�е� Entry ����(����һ�� Entry ��),��� bucketIndex ������û�� Entry ����,Ҳ��������������� e ������ null,Ҳ�����·���� Entry ����ָ�� null,Ҳ����û�в��� Entry ����
HashMap����û�г���hash��ͻʱ,û���γɵ�����ʱ,hashmap����Ԫ�غܿ�,get()�����ܹ�ֱ�Ӷ�λ��Ԫ��,���dz��ֵ�������,����bucket ��洢�IJ���һ�� Entry,����һ�� Entry ��,ϵͳֻ�ܱ��밴˳�����ÿ�� Entry,ֱ���ҵ��������� Entry Ϊֹ�������ǡ��Ҫ������ Entry λ�ڸ� Entry ������ĩ��(�� Entry ���������� bucket ��),��ϵͳ����ѭ�����������ҵ���Ԫ�ء�
������ HashMap ʱ,��һ��Ĭ�ϵĸ�������(load factor),��Ĭ��ֵΪ 0.75,����ʱ��Ϳռ�ɱ���һ������:���������ӿ��Լ��� Hash ��(�����Ǹ� Entry ����)��ռ�õ��ڴ�ռ�,�������Ӳ�ѯ���ݵ�ʱ�俪��,����ѯ����Ƶ���ĵIJ���(HashMap �� get() �� put() ������Ҫ�õ���ѯ);��С�������ӻ�������ݲ�ѯ������,�������� Hash ����ռ�õ��ڴ�ռ䡣 |